Overlay Multicast与主动 - 主动灾难恢复(Active-Active DR)
随着AWS云计算接收程度越来越高,很多公司已经意识到aws带来的具体好处。并且在云中不断增加功能以支持其越来越复杂的业务发展需求。
由于需要具备强大的架构体系结构来支持关键业务运营,因此使用AWS的公司依然严重依赖在主应用系统失效时,可以使用的灾难恢复系统。例如众多公司使用的CRM应用系统等。在任何其他情况下,迁移是一种直接的方法,但客户要求的要求使却更具挑战性。
挑战
客户面临的挑战是不仅要将所有的众多应用程序和非常多的数据库服务器迁移到AWS以进行灾难恢复,还需要在其数据中心与AWS云之间建立主动 - 主动灾难恢复(Active-Active DR)。他们的大多数平台。如果没有这个,客户很难有意愿迁移到云,因为他们需要具有同步DR以及强大的安全服务架构。但是对于如何完成这项工作却没有明确的方法,特别是考虑到客户需要一个主动 - 主动容灾(A-ADR)解决方案。 领云悠逸根据客户的要求构建详细的架构设计和迁移计划,并最终通过概念验证(POC)来确定其可行性。
解决方案
由于最终DR解决方案必须存在于AWS中,因此问题最终在于AWS环境如何与客户的数据中心保持主动 - 主动同步状态。根据客户确认,为了实现这一目标,理想的方法是通过使用多播(Overlay Multicast) (https://amazonaws-china.com/articles/overlay-multicast-in-amazon-virtual-private-cloud/) 实现。但是,AWS并不支持针对此特定需求的本地多播,因此最后确认围绕Overlay Multicast概念构建POC来解决。
通常情况下,AWS的许多客户不需要使用多播来支持其操作。但是,其实使用具有单播IP路由的IP级多播,就像AWS虚拟私有云(VPC)中的内容允许与其他AWS EC2对等点的点对点网络隧道一样。使用Packer模板,我们创建了一个带有预安装/预配置MCD守护程序的AMI,此守护程序用于在实例之间使用EC2标记自动创建GRE隧道,以发现同一多播组中的实例。然后安装了omping和iperf工具来检查多播工作和必要的iptables规则以允许GRE和多播流量。
测试过程逻辑图
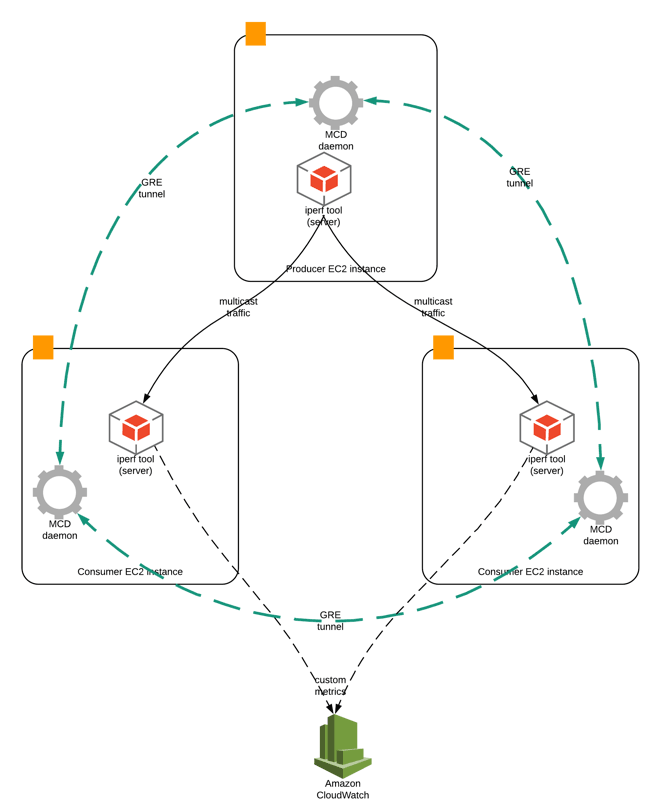
当各个应用程序创建和传输多播数据包时,该数据包将由本地实例接收,并为该信息的每个订户或消费者进行复制。
成果
在构建POC之后,为用户建立数据生产者以及Overlay Multicast实现的消费者。消息长度约为1500字节,测试带宽为500兆比特/秒。 采用Overlay Multicast方法,消费者的实际带宽平均达到大约59兆字节/秒,只有大约0.5%的软件包丢失,抖动率约为0.012毫秒。最终,确定由多播实现使用GRE隧道,因为生产者节点需要比消费者节点更大的尺寸,因为多播包将直接发送到每个消费者节点。
事实证明,POC是成功的,并最终满足了客户的需求。通过利用覆盖多播网络实施,验证了用于POC的架构设计和部署方法,以便在AWS中完全部署其基础架构。