小辉聊监控(2)
本周三,继续我们的小辉聊监控系列。详细这次依旧是满满“干货”。
监控的核心
发现问题:
当系统发生故障报警,我们会收到故障报警的信息
定位问题:
故障邮件一般都会写某某主机故障、具体故障的内容,我们需要对报警内容进行分析,比如一台服务器连不上:我们就需要考虑是网络问题、还是负载太高导致长时间无法连接,又或者某开发触发了防火墙禁止的相关策略等等,我们就需要去分析故障具体原因。
解决问题:
当然我们了解到故障的原因后,就需要通过故障解决的优先级去解决该故障。
总结问题:
当我们解决完重大故障后,需要对故障原因以及防范进行总结归纳,避免以后重复出现。注意哦,对于反复出现的报警,需要有针对性的分析。当然,如果确实数据太多且比较混乱,我们的消息送达服务MessageIn (http://linkyoyo.com/messageIn/), 特有的告警统计分析功能,可以通过从发出告警信息的角度发现那些潜在的问题,祝您一臂之力。
监控流程

说起来确实比较简单,但是把每个流程都做好,确实需要死磕每一个细节。
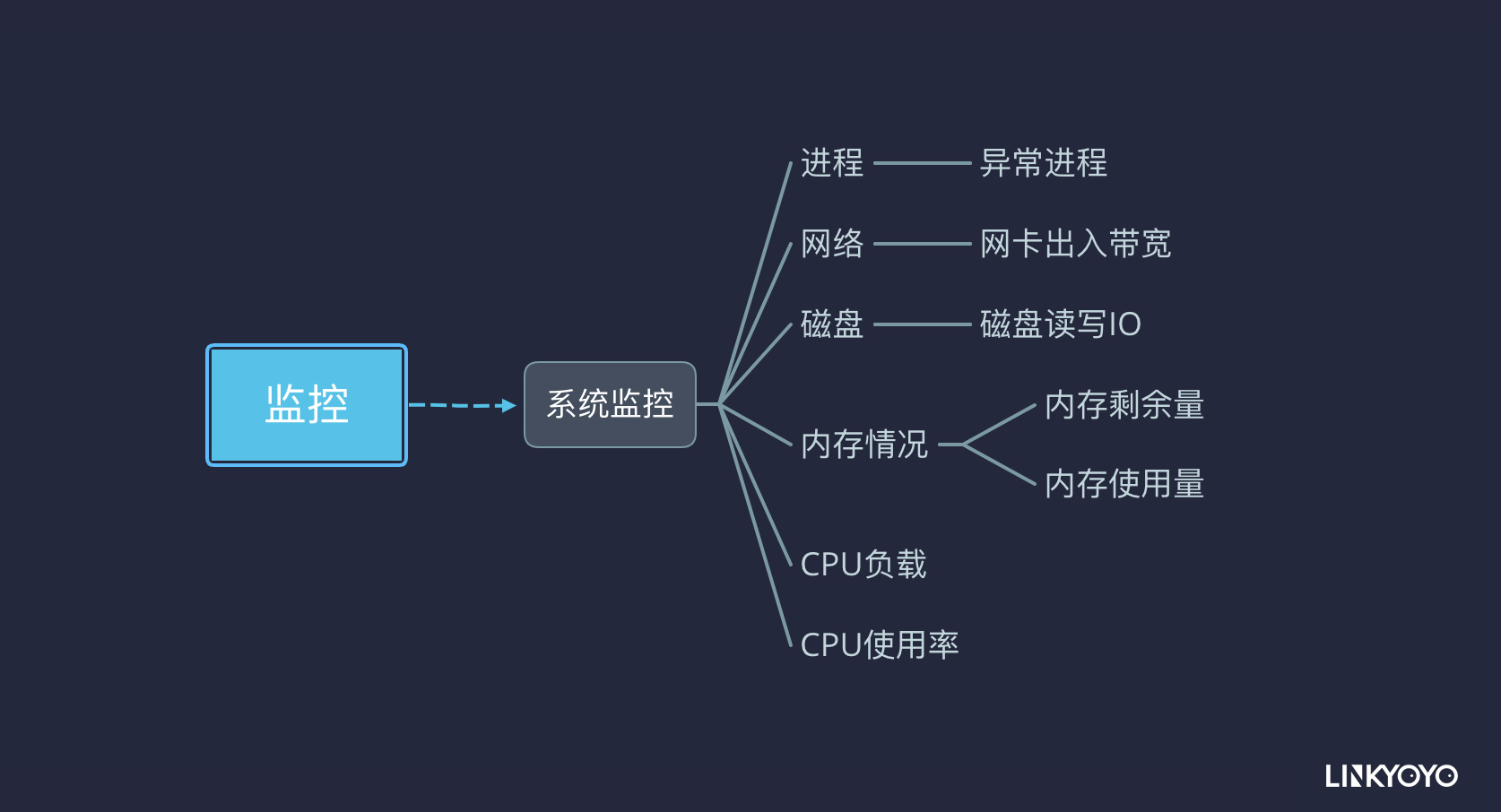
常用监控指标示例

系统监控
可用性监控:
cpu
cpu负载情况和cpu使用率是主要的监控指标,通常情况下cpu的使用率不要大于cpu的个数,常用的cpu查看命令:top htop
内存
通常我们需要监控内存的使用率、SWAP使用率、同时可以通过zabbix描绘内存使用率的曲线图形发现某服务内存溢出等。
IO
IO分为磁盘IO和网络IO。除了在做性能调优我们要监控更详细的数据外,那么日常监控,只关注磁盘使用率、磁盘吞吐量、磁盘写入繁忙程度,网络也是监控网卡流量即可。常用工具有:iostat、iotop、df、iftop
应用监控

基于业务的监控分为两块,一是保证业务的可用性,例如端口监控进程监控等。二是保证业务的正常运行,例如用户游戏充值失败等,没分钟产生多少个充值用户,一天有多少个活跃用户等等。
网络监控
网络监控是必不可少的,尤其是多机房之间的网络状态或者云和本地机房的网络状态及流量,网络监控可以清晰看到网络流量情况及带宽使用情况。
容器监控
随着docker的火热,Kubernetes编排工具也是越来越多被使用到正式环境,然而容器监控也是面临的一大挑战,现有监控无法快速的随着容器进行动态改变,而prometheus作为生态圈 Cloud Native Computing Foundation中的重要一员,其活跃度仅次于 Kubernetes,它的强大的多维度数据模型完美的结合了当下k8s的特性。
云监控
支持aws监控及告警,支持aws多指标进行告警分析,例如ec2的指标,rds的指标及ELB等指标,完美了结合了aws的cloudwatch,实现了对aws监控指标的二次存储及分析实现精准告警。
DB监控
对数据库的错误及性能进行监控是必不可少的,也是我们在寻找问题中的一个重要途径。对数据库连接数,使用内存,占有cpu等和对性能瓶颈的监控,队列情况,锁情况,慢查询情况。
这里罗列了不少,但是依旧有很多监控项目没有更为全面的展示和说明。且各位同仁估计在各自管理的系统上也有很多独特的监控和检查需求。监控就是首先全面列出监控项目,无论是横向列出(基于操作系统或IT平台)还是纵向(基于服务和某个项目)我们都需要更为全面的覆盖和不断的搜集整理和更新。我们自己的监控解决方案(Raptor)也是通过这样的迭代过程,逐步成长起来的。
下期,我们还有最后一次的小辉聊监控,小辉攻城狮将会继续和大家分享他的总结与创新。下周我们不见不散。